Understanding Gradient Descent: From a Beginner's Perspective
Heya! 👋 I love helping people, and one of the best ways I do this is by sharing my knowledge and experiences. My journey reflects the power of growth and transformation, and I’m here to document and share it with you.
I started as a pharmacist, practicing at a tertiary hospital in the Northern Region of Ghana. There, I saw firsthand the challenges in healthcare delivery and became fascinated by how technology could offer solutions. This sparked my interest in digital health, a field I believe holds the key to revolutionizing healthcare.
Determined to contribute, I taught myself programming, mastering tools like HTML, CSS, JavaScript, React, PHP, and more. But I craved deeper knowledge and practical experience. That’s when I joined the ALX Software Engineering program, which became a turning point. Spending over 70 hours a week learning, coding, and collaborating, I transitioned fully into tech.
Today, I am a Software Engineer and Digital Health Solutions Architect, building and contributing to innovative digital health solutions. I combine my healthcare expertise with technical skills to create impactful tools that solve real-world problems in health delivery.
Imposter syndrome has been part of my journey, but I’ve learned to embrace it as a sign of growth. Livestreaming my learning process, receiving feedback, and building in public have been crucial in overcoming self-doubt. Each experience has strengthened my belief in showing up, staying consistent, and growing through challenges.
Through this platform, I document my lessons, challenges, and successes to inspire and guide others—whether you’re transitioning careers, exploring digital health, or diving into software development.
I believe in accountability and the value of shared growth. Your feedback keeps me grounded and motivated to continue this journey. Let’s connect, learn, and grow together! 🚀
I recently started learning Machine learning, and one of the first concepts that I came across was Gradient Descent. At first encounter, it seemed too abstract (maybe because of the resource I was using).
I have put in some significant effort to learn more about it, and today I have decided to convert the notes that I made around this topic into a short blog post to give clarity on the topic for beginners who, like me, struggle to understand it.
I will start by explaining what gradient descent is and giving some analogies to drum it home. I will then proceed to share a practical life scenario, convert that to a project in Machine learning, and illustrate how to use gradient descent to solve this problem.
What is Gradient Descent?
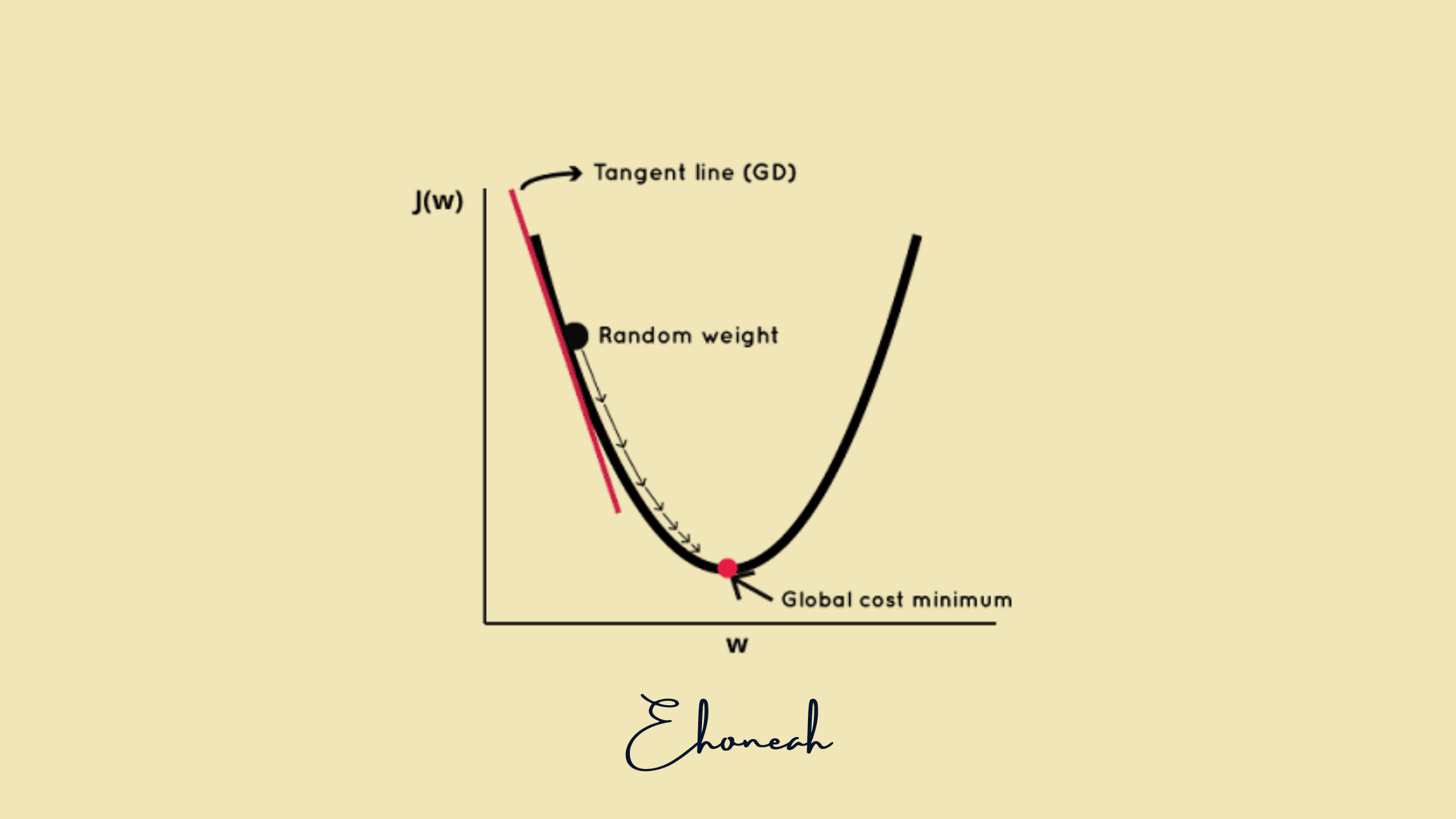
At its core, Gradient Descent is a method used to optimize functions. In the context of machine learning, it's an iterative approach to finding the best weight (or set of weights) for a given model. Think of it as a way to minimize the error or discrepancy between the predicted outputs and the actual outputs of a model.
Here is the analogy that helped me make sense of what gradient descent really is:
Imagine you're trying to find your way down hilly terrain in the dense fog. You can't see the bottom, but you can feel if you're moving uphill or downhill. Your goal is to reach the lowest point.
You don't have a map, so you take a step in the direction where the slope is steepest downward. With each step, you adjust your direction based on the terrain's slope. This is similar to how Gradient Descent works: it tweaks the weights bit by bit, aiming to find the lowest error (or the bottom of our hypothetical hill).
At its core, Gradient Descent is like a trial-and-error method. It's used to find the best possible weight (or parameter) that defines a given relationship or model. You can also think of it as tweaking the dials on a radio set until you get the clearest signal.
Types of Gradient Descent
While studying Gradient Descent, I discovered there are three main types:
Batch Gradient Descent
Stochastic Gradient Descent (SGD)
Mini-batch Gradient Descent
Let's delve into each (don't worry so much if you struggle to understand any part of this, I will soon illustrate with a practical example to clear things up):
Batch Gradient Descent: Here, the term 'batch' refers to the set of examples you use in a single training iteration. When you're using Batch Gradient Descent, you're essentially calculating the gradient using the entire dataset. While this can give a stable error gradient and a stable convergence, it can be computationally heavy and slow, especially for large datasets.
Stochastic Gradient Descent (SGD): A stark contrast to the Batch method, SGD takes just one example in each training iteration. This example is chosen at random. As a result, SGD can be faster since it doesn't require the entire dataset in every iteration. However, this comes at a cost: the error gradient can be noisy, leading to unpredictable movements. But, on the bright side, this randomness can help escape local minima.
Mini-batch Gradient Descent: As the name suggests, Mini-batch Gradient Descent strikes a balance between its two counterparts. In each iteration, it uses a subset of the dataset, typically containing about 10 to 1000 examples. This method combines the advantages of both Batch and SGD, offering faster computation while still maintaining a more stable error gradient.
A Practical Example of Gradient Descent: The Lemonade Stand
Imagine you're a child with a lemonade stand. You've noticed that the amount of sugar you add to your lemonade affects your sales. Too much sugar and it's too sweet; too little and it's too sour. You want to find the perfect amount of sugar to maximize your sales (This analogy reminds me of one of the technical interview questions I got when applying for my current role).
Setting Up the Problem
Let's treat the amount of sugar you add to the lemonade as the "weight" or parameter we want to optimize. The goal is to adjust this weight to find the best lemonade recipe that gives you the highest sales.
In machine learning terms:
Amount of sugar = Weight (or parameter)
Sales = Objective function (we want to maximize this)
Every day, you make a batch of lemonade with a certain amount of sugar and observe your sales. At the end of the day, you make a note of how well you did.
Let's see Gradient Descent in Action
On the first day, you start with a random guess. Let's say 5 spoons of sugar for a jug of lemonade. You notice that the sales are decent, but some customers mention it's a tad too sweet.
The next day, you decide to reduce the sugar by a small amount, say half a spoon, based on the feedback. This is the essence of Gradient Descent - adjusting the "weight" (sugar) based on the "error" (feedback).
As the days go by, you keep adjusting the sugar based on sales and feedback. Some days you increase it slightly, and some days you decrease it. Every time you make an adjustment, you're taking a step in the direction of the steepest descent—the direction that will reduce your error the most.
Types of Gradient Descent in Our Lemonade Stand
Batch Gradient Descent: Imagine waiting for a whole week, gathering feedback from every customer, and then making one adjustment to your lemonade recipe at the end of the week.
Stochastic Gradient Descent (SGD): This would be like adjusting your recipe after every single customer's feedback. A customer says it's too sweet, you reduce the sugar for the next glass. Another says it's too sour, you add a bit more sugar for the one after.
Mini-batch Gradient Descent: This is a middle ground. Let's say you adjust your recipe after every 10 customers. This way, you're not waiting too long like in Batch, but you're also not changing your recipe too frequently like in SGD.
Reaching the Sweet Spot
After several days (or iterations, in machine learning terms), you notice that there's a consistent amount of sugar that always results in the best sales. You've found the optimal weight!
That is the goal of Gradient Descent: to adjust the parameters (in our case, sugar) iteratively until you find the best possible value.
Gradient Descent, at its heart, is about making iterative adjustments to get to the best result. Whether it's the perfect lemonade recipe or a complex machine learning model, the principle remains the same. Start with a guess, measure how well you're doing, adjust based on feedback, and repeat until you find the best solution.
Key Takeaways
From my exploration of Gradient Descent, here are some terms you should familiarize yourself with:
Batch: The set of examples used in one iteration of training.
Batch Size: The number of examples in a batch.
Mini-batch: A subset of the dataset used in one iteration, usually containing between 10 to 1000 examples.
Stochastic Gradient Descent (SGD): A type of Gradient Descent where only one randomly selected example is used per iteration.
